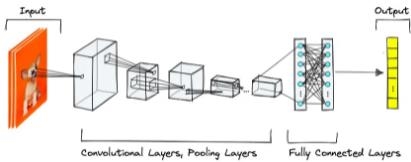
For instance, you might teach a computer not just how to look at a picture, but also how to *really* understand what it shows, such how a cat’s whiskers curl, how a person looks at a car, or how shadows change the design of a car. Convolutional Neural Networks (CNNs) do this by copying how well the human brain can pick out intricate visual patterns. CNNs use multilayer filters to change raw pixels into more abstract features that help machines “see” better.
Convolutional layers are digital filters that use small kernels to move across a picture. These are grids that check for basic parts like shapes, edges, and textures. When you execute a convolution, you produce a “feature map” that reveals where certain patterns are. You may look at objects from different levels by stacking these layers on top of each other. The highest levels take in simple shapes and edges, while the lowest levels join them together to build increasingly complicated shapes and items. This structure, along with *parameter sharing* and *local connectivity*, makes the network less demanding on computers and better at finding things no matter where they are or how huge they are.
Pooling layers make information even smaller by making the spatial dimensions smaller and summarizing feature maps. This makes the network less likely to react to small changes and distortions. These approaches, along with nonlinear activations like ReLU (Rectified Linear Unit), provide the CNN the ability to look at complex patterns in a flexible fashion and avoid overfitting by focusing on the most valuable characteristics. The network has turned raw visual input into a numerical fingerprint that can tell the difference between a puppy, a street sign, or a handwritten number with amazing precision by the time the data gets to fully connected layers.
Big businesses use CNNs in the real world to build visual technology that changes the game. CNNs that have been trained on large datasets help Google quickly and accurately discover pictures in its image search. Convolutional layers enable self-driving cars learn about their environment in real time, quickly and accurately recognizing people and other risks that could save lives. CNNs help radiologists find little problems in X-rays and MRIs that most people would miss. These examples highlight how convolutional layers are changing the way we think about what we see.
Here are some really useful things that show how CNNs “see”:
– **Removing Features in Layers:** The first layers can pick up on simple visual signals, such edges. Then, the deeper layers put these cues together to make more complicated thoughts that are relevant to the situation.
– **Parameters for Sharing and Spatial Invariance:** Learned filters can find patterns anywhere, which makes them simpler and more useful.
– **Pooling for Reducing Dimensions:** Pooling makes feature maps smaller, which means they are easier to look at and less influenced by changes in the image.
– **Activation Functions That Aren’t Linear:** ReLU adds important nonlinearity, which lets the network learn patterns that are more complex than merely putting pixels together.
– **Learning from the Start to the End:** You don’t have to make features by yourself because CNNs learn how to do it from raw pixels.
Convolutional layers provide machines this visual intelligence, which changes the way they see the world of images in a big way. CNNs are getting better at comprehending images in a way that is more like how people do it thanks to new technologies like attention mechanisms and deeper structures. Learning how convolutional networks “see” is a terrific approach to get a look at the most advanced technologies in both artificial and biological vision. It will help you understand how pixels and perception operate together.




