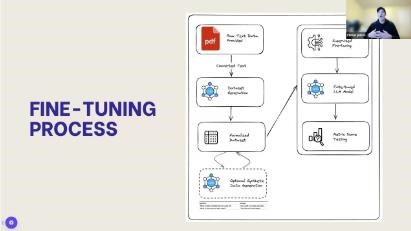
These days, it’s not too hard to update a small language model (SLM) using your own data. You don’t need a PhD to get the most out of AI. These little models operate well on low-end hardware, and you can utilize techniques like knowledge distillation and pruning to improve their performance.
For instance, LLaMA 3.1 is a simple model with 8 billion parameters that may easily change instructions. This model makes conversations more accurate, yet it doesn’t need as much data as base models do. Then, apply parameter-efficient fine-tuning (PEFT) techniques like LoRA (Low-Rank Adaptation). LoRA changes a lot of parameters by adding trainable low-rank matrices to layers that are already there. This method protects the model’s vital data while requiring less computer power.
Getting your dataset ready is quite important. Make sure your examples are clear, helpful, and of the highest quality. They should also look like templates for chatting or instructions on how to talk. You could use ChatML or ShareGPT, for instance. Getting solid data is really helpful for making sure the model works effectively where you live and for cutting down on hallucinations.
You might not imagine that open-source libraries like Hugging Face Transformers and PEFT or no-code platforms like Google AI Studio can help you do your job better and for less money. When you do iterative training to see how well the model works, you modify hyperparameters like the batch size and learning rate.
Nvidia improved the accuracy of code reviews by training tiny models on private code datasets. This proves that these strategies work well in real life. Microsoft’s Azure AI platform, on the other hand, proved that PEFT on small models made function calls work much better. This makes AI more helpful and adaptable without needing a lot of resources.
Deployment must utilize encryption and role-based access controls to make sure that only certain persons can get to the model after training. It also has to observe it all the time to see whether it becomes better and offer it new things to learn. It’s like taking care of a swarm of bees to take care of the model all the time. It gets bigger and more dependable with time.
To make a little language model operate successfully today, you need to use the correct tools, gather good data, and teach it the right way. If you want to and know how to do it, you can develop AI helpers that really help you with your problems. In the future, this means that practically everyone will be able to update AI like an expert.
—
**Ways to Make Your Small Language Model Better:
– Pick a base model that is made for teaching and works well with your program, such LLaMA 3.1 (8B parameters).
– Find knowledge that is valuable to your field and is written in a way that makes it feel like a conversation.
– Use LoRA or other fine-tuning approaches that work well with parameters to make changes that don’t take up too many resources.
– Use no-code tools like Google AI Studio or open-source toolkits like Hugging Face and PEFT to make it easier to train.
– To do iterative fine-tuning, tweak the hyperparameters and see how the quality of the result changes.
– Encrypt the model that is shared so that only some individuals can see it and keep the data safe.
– Look at the training dataset and tweak it often to make the answers better.
Anyone who wants to learn about AI can make a very useful tiny language model that matches their needs by carefully following these procedures. This makes it easy to understand and use the process of fine-tuning models, which used to be hard to get.